Tutorial
Required input data file
The input data must be a tabulated file (.tsv extension) with the following structure:
experiments |
time |
X |
Glucose |
|---|---|---|---|
Condition1 |
1 |
0.4 |
13 |
Condition1 |
2 |
0.6 |
12 |
Condition2 |
1 |
0.3 |
15 |
… |
… |
… |
… |
Columns time and X (biomass concentration) are mandatory, as is at least one metabolite column (Glucose in this example). If the biomass and metabolite concentrations were sampled at different moments, you can still group them together in the same table (with an empty value when no data is available). Column “experiments” contains the name of the condition/experiment, which must be provided even if only one condition/experiment is being analyzed.
Note
Flux units depend on the units of time and concentrations (of biomass and metabolites) provided in the input data file. For instance, if biomass units are in grams of cell dry weight by liter (gCDW/L), metabolite concentrations are in millimolar (mM) and time is in hours (h), the estimated fluxes will be in mmol/gCDW/h. Units should thus be carefully selected, and calculated fluxes must be interpreted consistently with the concentration units.
Warning
The “experiments” column must only contain letters (no numbers) and is case-sensitive!
Warning
To limit any numerical instabilities, we recommend providing values in a range not too far from unity (e.g. if a metabolite concentration is 2 mM, provide the value directly in mM and not as 0.002 M). The concentration of different metabolites can be provided using different units, but a single unit must be used for a given metabolite.
Configuration file (yaml)
The yaml configuration file contains all parameters required to calculate fluxes for a given experiment, and is
thus key to ensure reproducibility of the flux calculation process. A configuration file is generated automatically by
PhysioFit during flux calculation; it can also be created or edited manually.
Here is an example of a configuration file:
iterations: 100
mc: true
model:
bounds:
Ace_M0: (1e-06, 50)
Ace_q: (-50, 50)
Glc_M0: (1e-06, 50)
Glc_q: (-50, 50)
X_0: (0.001, 10)
growth_rate: (0.001, 3)
model_name: Steady-state batch model
parameters_to_estimate:
Ace_M0: 1
Ace_q: 1
Glc_M0: 1
Glc_q: 1
X_0: 1
growth_rate: 1
path_to_data: ..\data\test-data_single_exp.tsv
sds:
Ace: 0.2
Glc: 0.2
X: 0.2
For a description of all calculation parameters, check the section below.
Flux calculation parameters
The first parameter is related to the sensitivity analysis (Monte-Carlo), for which a check box indicates whether PhysioFit should estimate (or not) the precision on calculated fluxes. If checked, PhysioFit will let you select the number of Monte Carlo iterations. A higher number of iterations means more accurate confidence intervals on the estimated parameters, but will slow down calculations. The default number of iterations (100) is sufficient in most situations.
Next, the list of run parameters that you can tweak depends on the model you have selected. There are two types of parameters: i) parameters to estimate, for which you can change the solution space bounds and the initial values and ii) fixed parameters for which you can change the value. Here is an example when the steady-state without lag and with metabolite degradation model is selected:
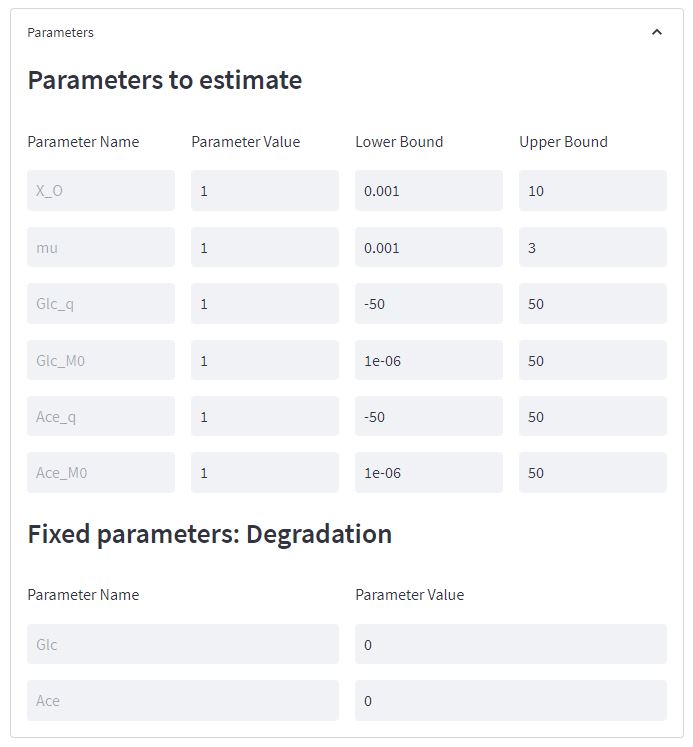
Standard deviation on measurements. As detailed in the methods section, reducing the standard deviation will increase the cost of the corresponding data during the optimization, thereby forcing an improvement of the fit accuracy for this measurements, but degrading the goodness-of-fit for the other measurements.
Finally, Verbose logs: Should debug information be written in log file. Useful in case of trouble (please join it to the issue on github). Default: False
Other default initial values are given by the model.
Note
Initial values and bounds should be carefully chosen. Ideally, initial values should be in the range of values used in the experiment. Well-defined bounds will enhance robustness and speed of the flux calculation process. The default bounds are sufficient in most cases, but may still be defined by the user when needed (e.g. the higher bound on initial metabolite concentrations should be increased if the initial concentration of substrate is higher than 50, since it is the maximal value allowed by default.).
Output files
The following files are generated by PhysioFit in the output directory:
config_file.yamlconfiguration file containing all parameters used for the last run.
flux_results.tsvflux calculation results, i.e. fluxes and initial metabolite concentrations for the best fit, with associated precision.
stat_results.tsvresults from the χ² and AIC statistical tests (see Method for more details on the statistical tests performed by PhysioFit).
log.txtrun log file containing information on how the run went.
plots.pdfplots of simulated and measured data.A number of
.svgfiles: individual plots of simulated and measured data.
summary.csv: summary of flux results (useful when multiple experiments are analyzed)
Note
When the data file (and not a
yamlconfiguration file) is directly used as input in the Graphical User Interface, PhysioFit cannot get the path directly from the file metadata. For this reason,path_to_datais set toNonein the generatedconfig_file.yaml.PhysioFit silently overwrites (results and log) files if they already exist. So take care to copy your results elsewhere if you want to protect them from overwriting.
The quality of the fit must be checked before interpreting the estimated fluxes. You can check the test_results.tsv
file, which contains the detailed χ² statistical test results and a clear status on the quality of the fit (based on a
95% confidence interval). The generated plots also help to visualize how accurately the simulated data fits the
experimental measurements. Finally, the confidence intervals estimated using the Monte-Carlo approach provides
quantitative information on the precision of the estimated fluxes (mean, median, standard deviation and 95% confidence
interval). Have a look to the Frequently asked questions (FAQ) section for help on interpreting the statistical results.